是我创造了首个 LLM:Kaggle 前首席科学家一句话引发 AI 学术圈考古行动
2025-04-09 12:19:10 小编:唐佳软件园
论如何在技术圈争论中一句话噎到对方:
哥们,是我创造了第一个大语言模型。
发言者 Jeremy Howard 为澳大利亚昆士兰大学名誉教授、曾任 Kaggle 创始总裁和首席科学家,现 answer.ai 与 fast.ai 创始人。

事情的起因是有人质疑他最近的项目 llms.txt 在帮助大模型爬取互联网信息上并没太大作用,从而引发了这段争论,迅速引起众人围观。
闻讯而来的“赛博考古学家们”一番考据之后,发现第一个大语言模型这个说法还真有理有据:
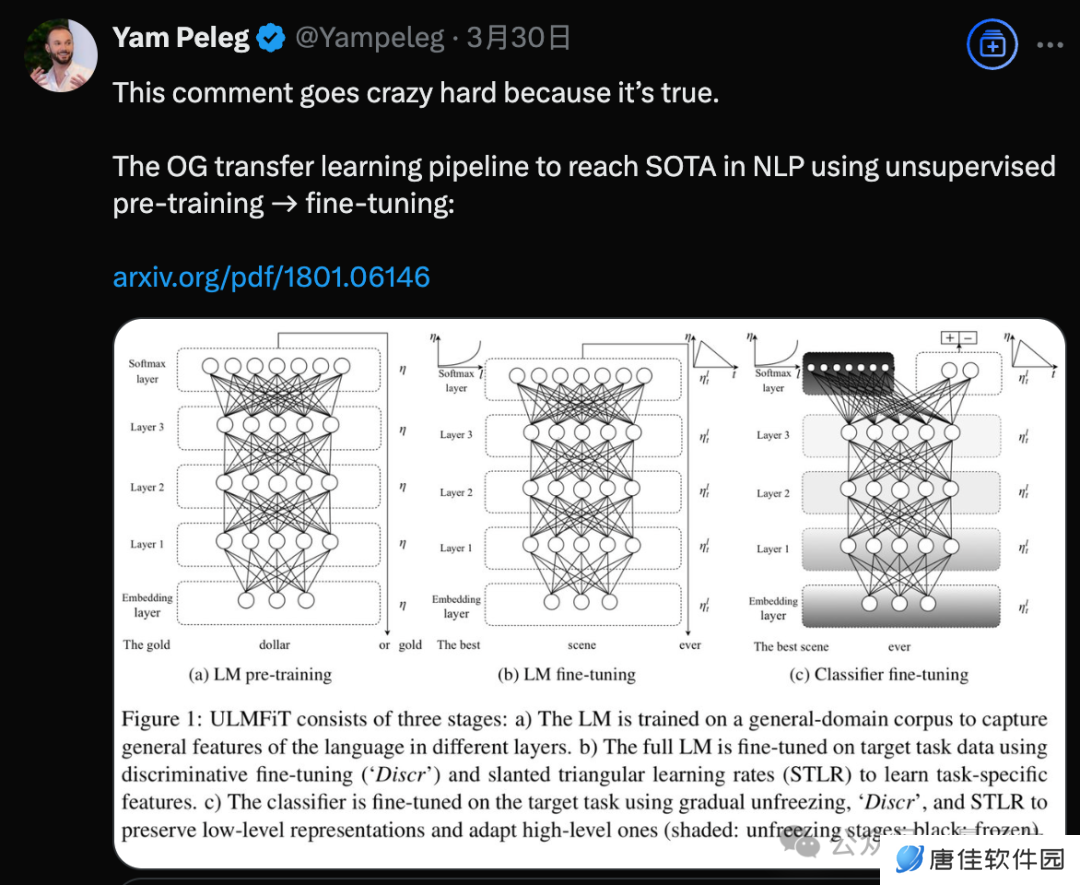
2018 年初,Jeremy Howard 发表的论文 ULMFiT,使用非监督预训练-微调范式达到当时 NLP 领域的 SOTA。
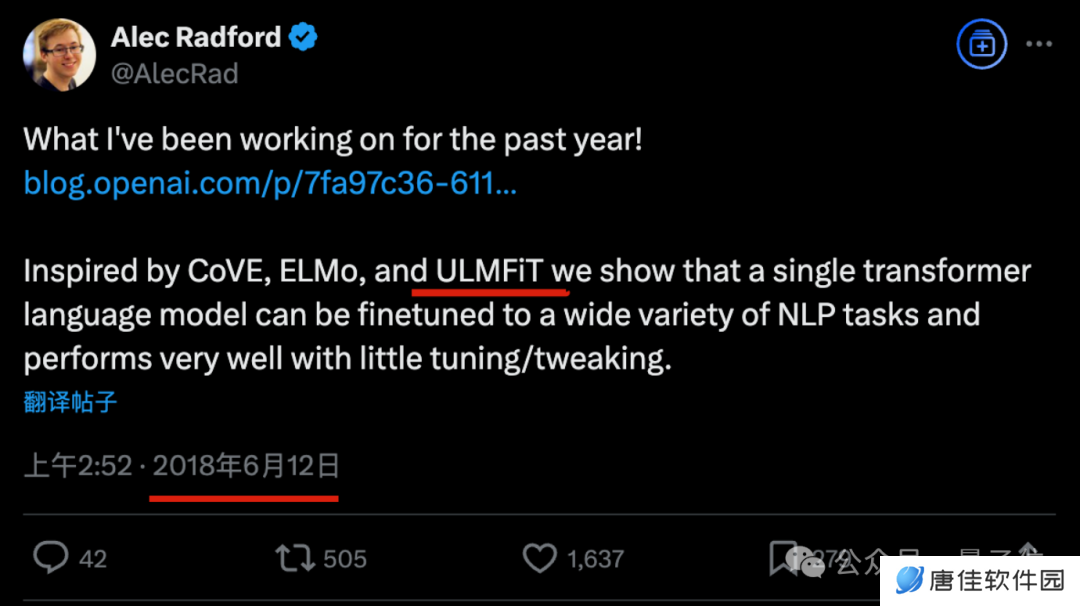
甚至 GPT-1 的一作 Alec Radford,在发表 GPT-1 时也公开承认过 ULMFiT 是灵感来源之一。
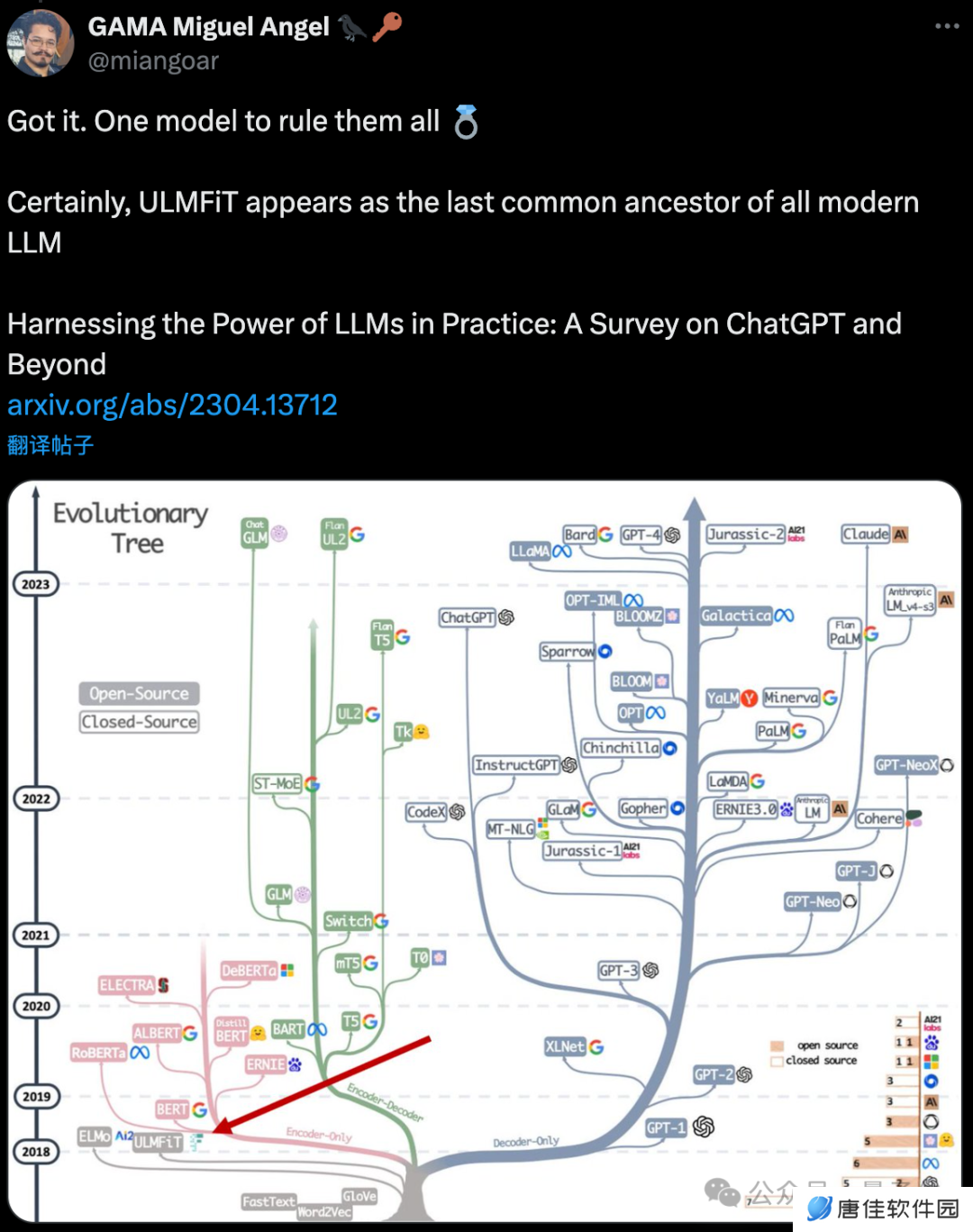
有人搬出综述论文,指出从“遗传学”视角看,ULMFiT 是所有现代大模型“最后的共同祖先”。
还有好事者软件工程师 Jonathon Belotti,专门写了一篇完整考据《谁才是第一个大语言模型》

大语言模型起源考据
首先来介绍一下 ULMFiT 这篇论文,入选 ACL 2018:
提出有效迁移学习方法,可应用于 NLP 领域的任何任务,并介绍了微调语言模型的关键技术,在六个文本分类任务上的表现明显优于当时的 SOTA 方法,在大多数数据集上将错误率降低了 18-24%。此外,仅使用 100 个带标签的示例,它的性能就与在 100 倍以上数据上从头开始训练的模型性能相当。

那么 ULMFit 算不算第一个大语言模型呢?Jonathon Belotti 考据遵循这样的思路:
首先找一个大家都公认肯定算大语言模型的成果,GPT-1 肯定符合这个标准。
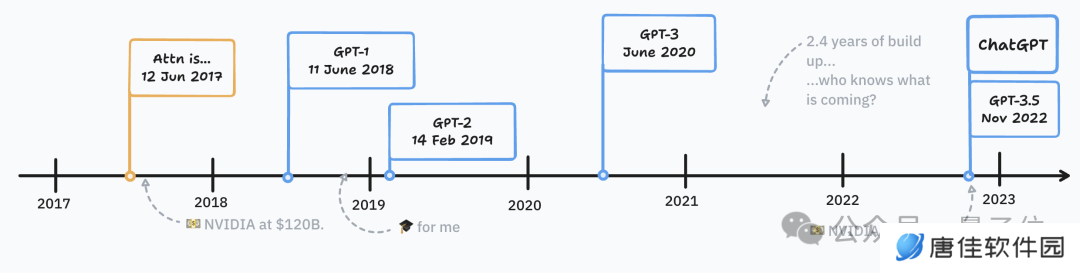
再从 GPT-1 和后续 GPT-2、GPT-3 中提取一个模型成为成为大语言模型的标准:
[1]https://x.com/jeremyphoward/status/1905763446840607164
[2]https://thundergolfer.com/blog/the-first-llm
首先要是一个语言模型,根据输入预测人类书面语言的组成部分,不一定是单词,而是 token
核心方法是自监督训练,数据集是未标记的文本,与此前特定于任务的数据集有很大不同
模型的行为是预测下一个 token
能适应新的任务:不需要架构修改,就有 few-shot 甚至 one-shot 能力
通用性:可以先进的性能执行各种文本任务,包括分类、问答、解析等
接下来分析 GPT-1 引用的几个重要模型:原版 Transformer,CoVe,ELMo 和 ULMFiT。
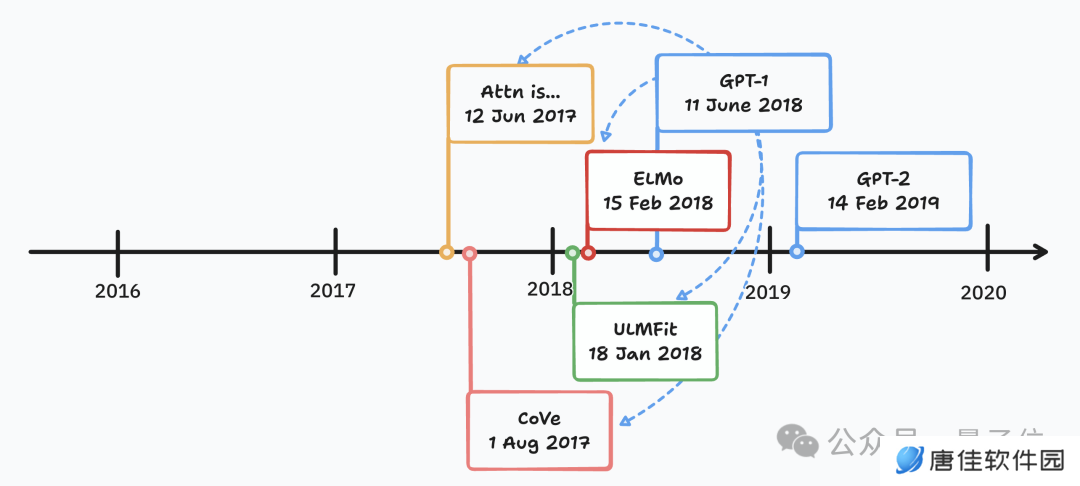
Transformer 虽然是现代主流大模型的架构基础,但原版只用于机器翻译任务,还不够通用。同时非 Transformer 架构如 LSTM、Mamba 甚至 Diffusion 也可被视作大型语言模型。
CoVE 提出了语境化词向量,是迁移学习领域的一项重要创新,但它通过监督学习训练(英语翻译德语)创建向量,不符合自监督学习的条件。
ELMo 使用了自监督预训练和监督微调范式,但在 few-shot 能力上还差点意思。
总之在作者 Jonathon Belotti 看来,CoVE 和 ELMo 都还没达到大语言模型的门槛。
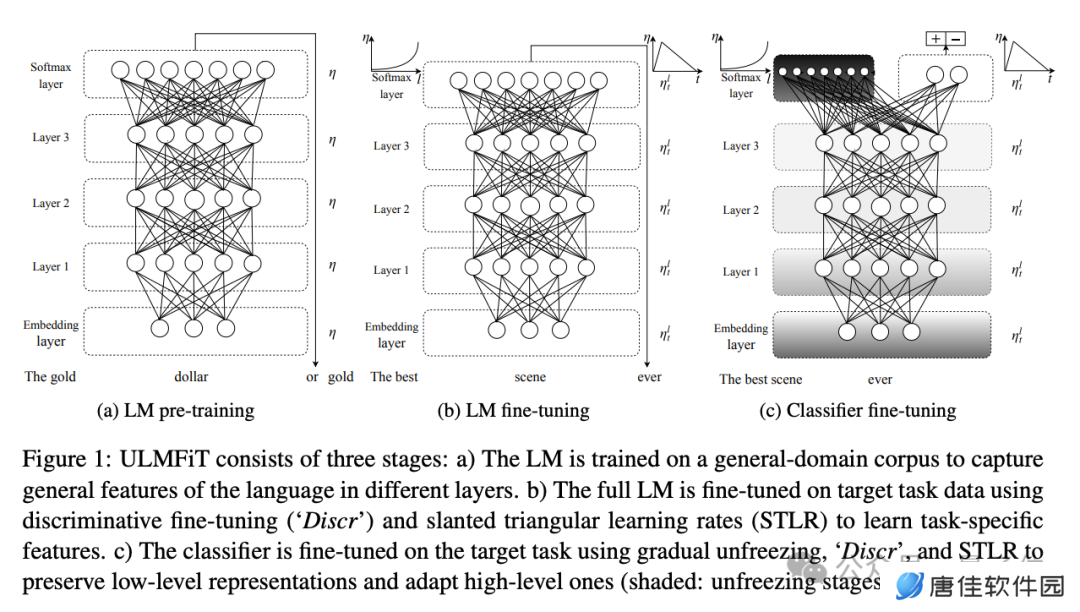
最后再来看 ULMFiT,其名字代表在文本分类任务微调的通用语言模型(Universal Language Model Fine-tuning for Text Classification)。
它是一个在 WikiText 数据上自监督训练的 LSTM 模型,能够以低成本适应新任务,无需更改架构即可执行大量文本分类任务,且达到当时的 SOTA 性能。
与 GPT-1 相比,只差在微调不够方便,以及应用任务的广度。
GPT-1 论文原文中,也指出“最接近我们工作的”就是 ULMFiT 与谷歌的半监督序列学习(Semi-supervised Sequence Learning)了。
GPT-1 论文还声称,把 LSTM 换成 Transformer 后能拓展预训练模型的预测能力,比 ULMFit 任务适应性更高。

考据者 Jonathon Belotti 最后总结到:
成为第一重要么?我认为有一点重要。软件行业和学术界尊重其创始人,我们都是开源社区中构建开拓智域文化(homesteads the noosphere)的一部分。
而 Jeremy Howard 本人对此的后续回应是我们创造了第一个“通用语言模型”,但后续论文没有沿用,反而创造了“大型语言模型”这个新术语。

苹果工程师 Nathan Lawrence 认为,虽然今天大家对谁是第一个 LLM 可能存在争议,但最终大家都会把 ULMFiT 视为一个转折点。
当时即使我这样的怀疑论者,也快开始意识到大规模通用训练将成为 NLP 的未来。

也有人建议 Jeremy Howard 以后说 ULMFit 是第一个“通用预训练模型”。
“我发明了 ChatGPT 中的 GP”,这句话说起来也很酷,一点也不夸张。
ULMFit
https://arxiv.org/abs/1801.06146
GPT-1
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
参考链接:
- 猜你喜欢
-
 苹果蛇蛇大作战 v1-超强智力大挑战的贪吃蛇!9.9MB手游下载
苹果蛇蛇大作战 v1-超强智力大挑战的贪吃蛇!9.9MB手游下载 -
 粉色视频最新版9.9MB手游下载
粉色视频最新版9.9MB手游下载 -
 抖阴破解版最新版9.9MB手游下载
抖阴破解版最新版9.9MB手游下载 -
 小小的便利店 v1-在校园中开一家属于自己的小卖部吧9.9MB手游下载
小小的便利店 v1-在校园中开一家属于自己的小卖部吧9.9MB手游下载 -
 选王之剑240.01MB手游下载
选王之剑240.01MB手游下载 -
 试管水排序解谜-解压倒水排序 v1.00-试管水排序9.9MB手游下载
试管水排序解谜-解压倒水排序 v1.00-试管水排序9.9MB手游下载 -
 暗影游侠756.78MB手游下载
暗影游侠756.78MB手游下载 -
 后室追逐 v1.0-一款非常好玩的恐怖冒险手游9.9MB手游下载
后室追逐 v1.0-一款非常好玩的恐怖冒险手游9.9MB手游下载 -
 魔法之门Online155.3MB手游下载
魔法之门Online155.3MB手游下载









- 相关手机游戏
-
 莉莉公主梦3 v5.0.0-体验一把设计师的快乐,来DIY吧9.9MB手游下载
莉莉公主梦3 v5.0.0-体验一把设计师的快乐,来DIY吧9.9MB手游下载 -
 妖神记之巅峰对决 v1.0-妖神记正版授权手游9.9MB手游下载
妖神记之巅峰对决 v1.0-妖神记正版授权手游9.9MB手游下载 -
 我要当店长-5月17日删档测试 v1.9.3.67-逆袭吧,打工人!9.9MB手游下载
我要当店长-5月17日删档测试 v1.9.3.67-逆袭吧,打工人!9.9MB手游下载 -
 蜀山战神0173.06MB手游下载
蜀山战神0173.06MB手游下载 -
 神龙吞噬吧 v5.0.0-想活下去就全靠吞!!9.9MB手游下载
神龙吞噬吧 v5.0.0-想活下去就全靠吞!!9.9MB手游下载 -
 打工模拟器 v01.240517.1-来建造属于你自己的海上度假村吧!9.9MB手游下载
打工模拟器 v01.240517.1-来建造属于你自己的海上度假村吧!9.9MB手游下载 -
 IartBook73.84 MB手游下载
IartBook73.84 MB手游下载 -
 帝王三国经典版89.74MB手游下载
帝王三国经典版89.74MB手游下载 -
 永年论坛安卓版59.80 MB手游下载
永年论坛安卓版59.80 MB手游下载









- 推荐精选导读
- 是我创造了首个 LLM:Kaggle 前首席科学家一句话引发 AI 学术圈考古行动
- CallKit 功能将至,微信鸿蒙版 App 1.0.5.36 邀测版本新增 voip 代码
- 长安汽车 4 月新品计划公布,含阿维塔 06 / 07 探索版、启源 Q07 等 9 款车型
- 关税阴影下美国人恐慌性抢购 iPhone,苹果周末销售额远高于往年同期
- 竞争力不及中国厂商:欧洲电池材料商呼吁整合时机已到,过去一年股价跌超 50%
- OPPO 100W 小方瓶超级闪充氮化镓充电器亮相,支持 65W PD 保持长期功率不掉电
- Steam 一周游戏销量榜:《Schedule I》二连冠,《双影奇境》登顶国区
- 《黑帝斯 2》确认将率先登陆任天堂 Switch 平台,后续上线 Xbox、PS5 主机
- 24 款比亚迪宋 L EV 汽车获 2.0.0 版本 OTA,新增哨兵模式、千里眼等功能
- 超仿真:全球首款可拉伸电子皮肤触觉传感器产品亮相,能感知 1 克物体所产生的力
- 最新手机精选
-
 ehviewer绿色版1.9.9.92025-03-24手游下载 | 8.92 MB
ehviewer绿色版1.9.9.92025-03-24手游下载 | 8.92 MB -
 e站(ehviewer)最新版2025-03-25手游下载 | 9.13 MB
e站(ehviewer)最新版2025-03-25手游下载 | 9.13 MB -
 ehviewer绿色版1.9.9.02025-03-24手游下载 | 7.22 MB
ehviewer绿色版1.9.9.02025-03-24手游下载 | 7.22 MB -
 ehviewer白色版1.9.9.92025-03-25手游下载 | 9.81 MB
ehviewer白色版1.9.9.92025-03-25手游下载 | 9.81 MB -
 JMComic2025-03-25手游下载 | 9.13 MB
JMComic2025-03-25手游下载 | 9.13 MB -
 ehviewer彩色最新版2025-03-24手游下载 | 7.25 MB
ehviewer彩色最新版2025-03-24手游下载 | 7.25 MB






- 推荐阅读阅读排行
-
-



- 推荐下载下载排行
-
-



